1. Github : https://github.com/snrndi121/visionVoice
snrndi121/visionVoice
[우수상] Future Finance AI Challenge (seperate voice from vision) - snrndi121/visionVoice
github.com
2. 설계도
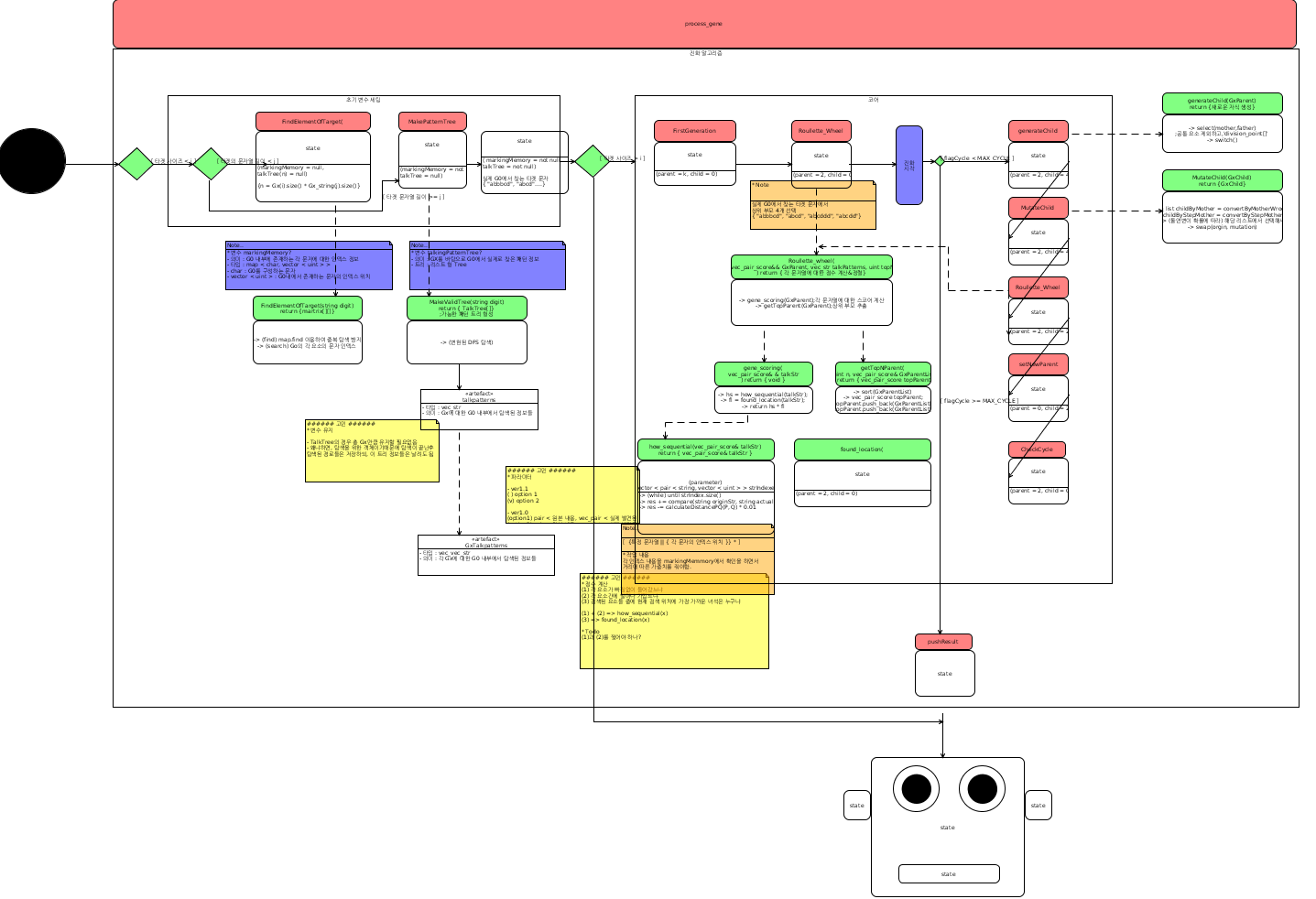
2.1 초기 세대 생성
- 탐색 베이스(src) G0의 각 요소 문자의 인덱스 리스트 생성, markingMemory
- markingMemory와 탐색 대상(dst) Gx를 기반으로 G0에서 유사 패턴, talkTree
2.2 룰렛휠
- talkTree를 기반으로 일정 수식에 따라서 각 패턴에 대하여 점수화
- 상위 Top N개(현재는 4개)로 정렬 후, 진화 알고리즘 적용
2.3 자식세대 생성
- 세대간 공통 요소를 제외하고 division point[] 잡고 switch
- 룰렛휠에 의한 선정 후 새로운 부모세대로 지정
2.4 돌연변이
- 데이터 특성(모음의 변형 가능 형태 고려)에 따라서 "치환 형태"로 일정 확률(0.01%)로 발생
3. 방향
3.1 현실적 입력 데이터 고려
- (현재) 단순한 문자열 -> (향후) struct 타입의 {문자, 타이밍}
- 이를 반영하여 탐색 기법 변화
3.2 탐색 방법
- (현재) 유전 알고리즘에 기반한 Index = 0부터 패턴 검색 -> (향후) 타이밍 기점으로 [head-tail] 양단을 옮겨가며 패턴 검색
4. 참고
https://untitledtblog.tistory.com/110
[최적화/전역 최적화] 유전 알고리즘 (Genetic Algorithm)
1. 소개 유전 알고리즘은 생물체가 환경에 적응하면서 진화해가는 모습을 모방하여 최적해를 찾아내는 검색 방법이다. 유전 알고리즘은 이론적으로 전역 최적점을 찾을 수 있으며, 수학적으로 명확하게 정의되지..
untitledtblog.tistory.com
'영상 화자 분리 > 설계' 카테고리의 다른 글
| [개발예정] 입술 분류 계획 (0) | 2020.04.23 |
|---|---|
| [텍스트 매칭] KMP & Gene algorithm (0) | 2020.04.03 |